RaC: Robot Learning for Long-Horizon Tasks by Scaling Recovery and Correction
TL;DR:
RaC achieves efficient performance scaling via a "mid-training" phase added after imitation pre-training.
In this phase, RaC scales recovery & correction data via human intervention data collection.
Learning on diverse skills data enables policies to reset, retry, and adapt, mitigating compounding errors in long-horizon manipulation tasks.
RaC standardizes human intervention data collection protocols with two rules:
- Upon intervention, operators first recover back to in-distribution states, then perform correction to complete the sub-task.
- After intervention completes, operator terminates the episode to prevent further rollouts.
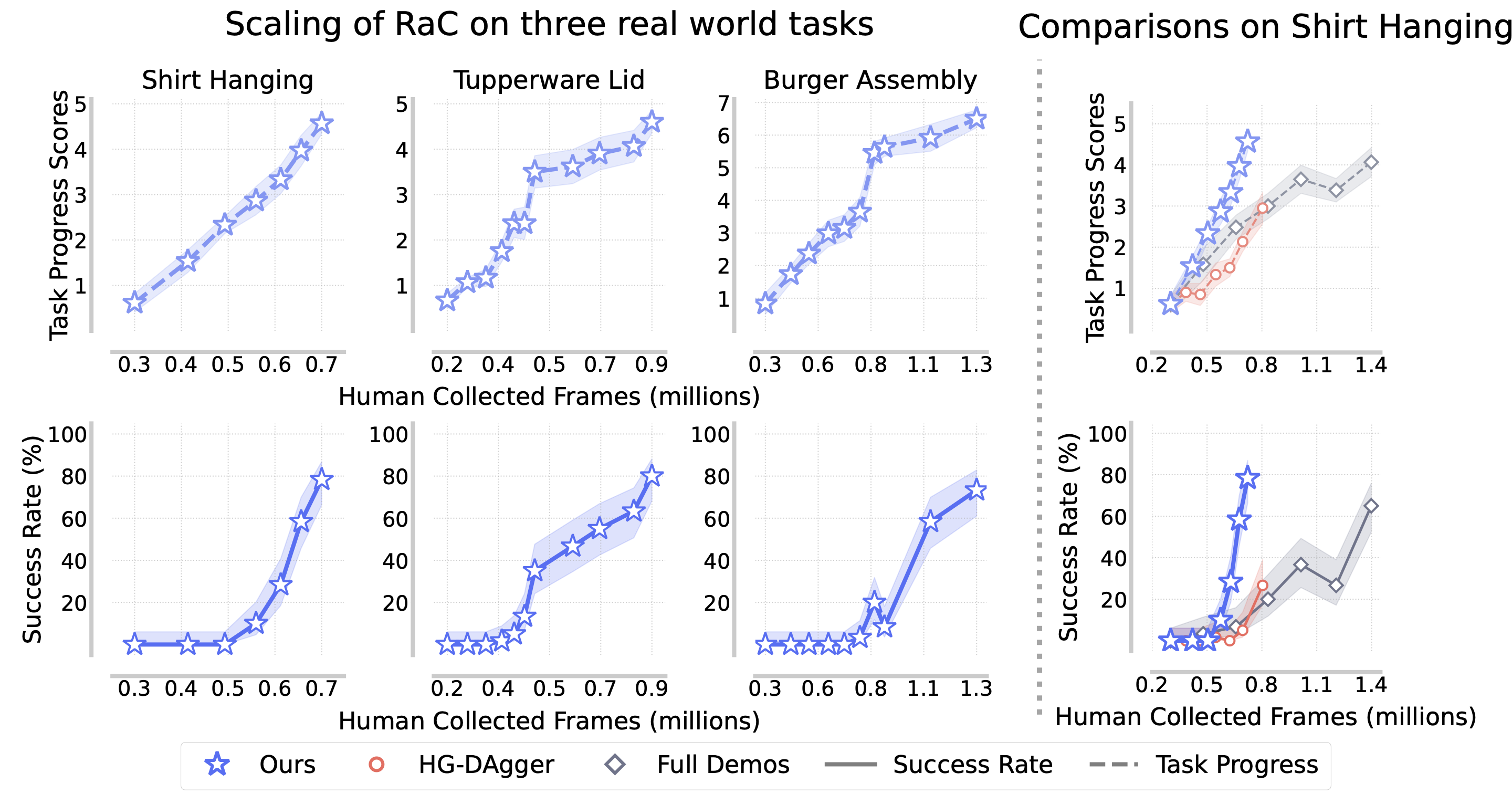
On challenging real world long-horizon manipulation tasks, RaC achieves high success rates with efficient data scaling. It outperforms prior human-in-the-loop method HG-DAgger and conventional batched full expert trajectories data collection.
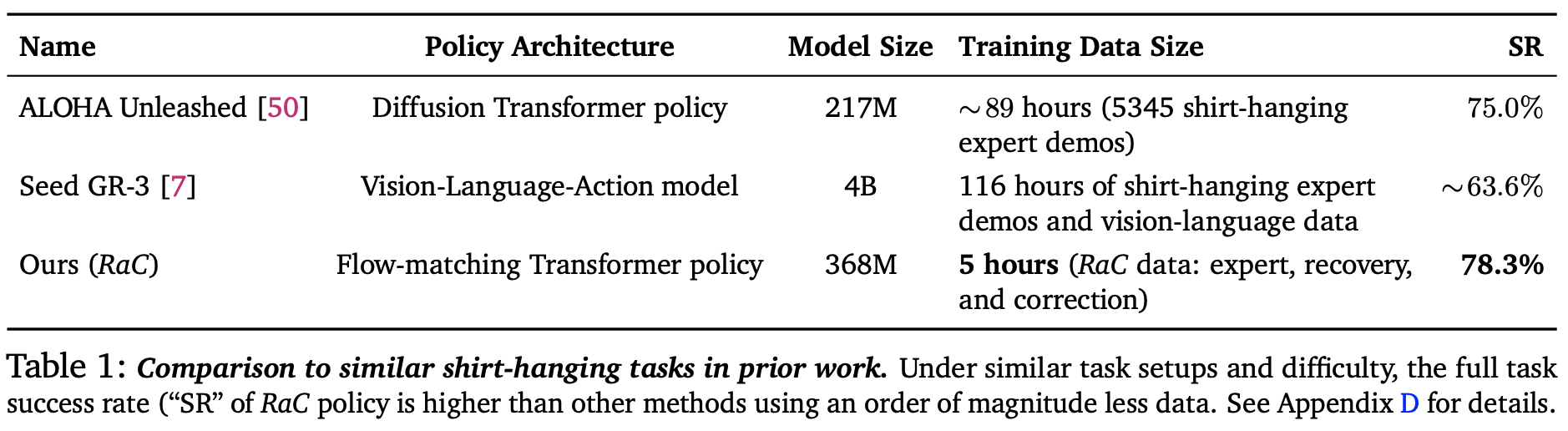
Compared to previous SOTA results on similar shirt-hanging task, RaC outperforms prior approaches with ~10x less data.
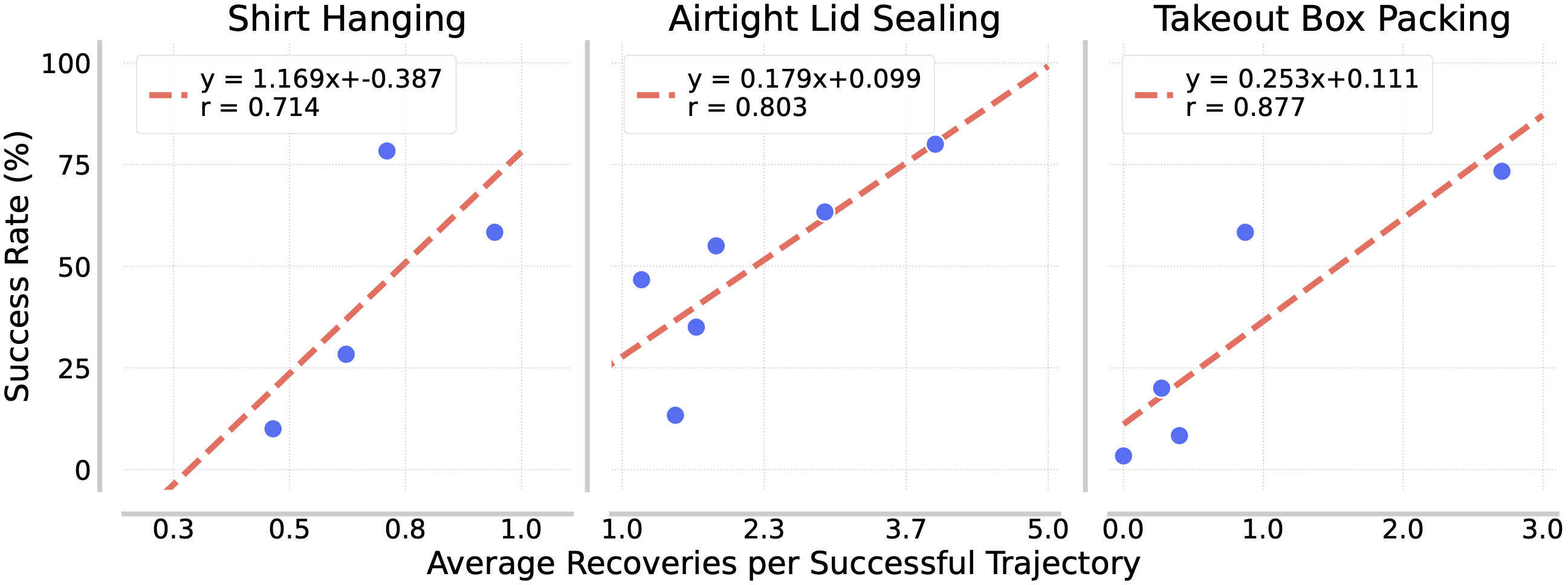
During deployment, RaC exhibits test-time scaling characteristic — full task completion success rises with more recovery behaviors.
RaC Data Collection Protocol
(Click Video to Play)
Recovery & Correction Improves Robustness to Failures
All Videos are autonomous policy rollouts recorded at 1x speed.
Learned Policies Comparison
(Click Video to Play)
Shirt Hanging
The robot recovers from left shoulder insertion failures many times.
The robot recovers from both right and left shoulder failures.
The robot recovers from both right and left shoulder failures.
The robot fixes left shoulder insertion and the final hanging.
The robot succeeds without making mistakes.
The robot recovers from left shoulder insertion failure.
Airtight Container Lid Sealing
The robot consistently recovers from snapping failures.
This example recovers from a tab snapping failure.
This video shows reactive recovery from failed lid placement.
The robot recovers from minor lid placement imperfection.
The robot successfully seals the lid without making mistakes.
Clamshell Takeout Box Packing
The robot succeeds packing a burger into a takeout box without making mistakes.
The robot detects failed attempts at the final stage, then recovers from them and correctly completes the task.
The robot recovers from incorrectly grasping the spatula.
The robot recovers from misaligned grasping spatula and securing tab failures.
The robot recovers from failed grasping of the spatula, performs corrections for scooping the burger, detects and recovers from a failed attempt at the final stage.
Uncut Shirt Hanging Full Evaluation Recording (60 Trials, 2 Hours)
Out of 60 evaluation trials, the robot achieved 48 full task successes, 80% task success rate.
BibTeX
@misc{hu2025racrobotlearninglonghorizon,
title={RaC: Robot Learning for Long-Horizon Tasks by Scaling Recovery and Correction},
author={Zheyuan Hu and Robyn Wu and Naveen Enock and Jasmine Li and Riya Kadakia and Zackory Erickson and Aviral Kumar},
year={2025},
eprint={2509.07953},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2509.07953},
}